
It’s quite common for an e-commerce application to offer similar products for a specific item. To meet this requirement, several approaches can be taken. For instance, we could display a number of products within similar categories or retrieve similar products by analyzing tags and generating suggestions. However, these methods are somewhat static and may not consistently provide the best recommendations. A more effective approach involves utilizing TF-IDF vectorization and Cosine Similarities to find similar products.
Text Vectorization
Before diving into the specifics of TF-IDF, let’s refresh our memory on text vectorization. Text vectorization involves converting textual information, such as product information, into a numerical format that computers can interpret and analyze. Once text vectorization is complete, the resulting numerical data becomes usable for more sophisticated linguistic tasks.
Here we’ve showcased the process of converting text data into a term-document matrix, also known as a bag of words, which is a straightforward method of text vectorization. While this approach is user-friendly, it only considers the frequency of each word in the document and doesn’t account for the importance of overly common words. Consequently, this can lead to ambiguous results when comparing documents for similarities and differences. For instance, documents may seem similar if they contain comparable stop words (like “was”, “is”, “to”, and “the”, etc) that frequently appear. Hence, it’s crucial to give more weight to distinctive words that accurately represent the content of each document.
TF-IDF
Now that we’ve acknowledged the limitations of the term-document matrix (or bag of words) in capturing unique and significant words for accurate content representation, it’s evident that we need a better alternative. Enter the Term Frequency-Inverse Document Frequency, commonly known as TF-IDF. But before delving into TF-IDF, let’s break down what term frequency (TF) and inverse document frequency (IDF) means.
Term frequency, abbreviated as TF, signifies the importance of a specific word within a given document. But why do we assign weights to individual words in documents? The primary reason is the varying lengths of documents. Each document may contain a different number of words, resulting in significant differences in document lengths. For instance, consider searching for a particular word in two documents: one with 15 words and another with 150 words. The longer document is more likely to contain the word compared to the shorter one. To ensure comparability between documents, the counts of word occurrences need to be normalized based on the length of each document. TF achieves this normalization by dividing the frequency of a word by the total number of words in the document.

Where,
t = Frequency of a word in a document
d = Total number of words in the document
Let’s explore a simple example illustrating the calculation of TF. Suppose we have two documents. In the first document, the sentence is: “John eats raspberry” Here, the word “John” appears once. Hence, the TF value for “John” is calculated as 1/3=0.333. In the second document, the sentence reads: “John eats apple and berry.” This document contains five words, and “John” appears once. Consequently, the TF value for “John” is 1/5=0.2.
When a specific word is absent from a document, its TF value in that document is 0. Conversely, if a document contains only that word and no others, its TF value for that word is 1. Therefore, the TF value falls within the range of 0 to 1. Words that occur frequently within a document possess higher TF values, while less common words have lower values.
Unlike TF, inverse document frequency (IDF) indicates the significance of a specific word across all documents. The term “inverse” is used because as the number of documents containing a particular word rises, the weight of that word diminishes. IDF achieves this by computing the logarithm of the ratio between the total number of documents and the number of documents containing the word.

Where,
- N = Total number of documents in the corpus
- df(t) = Number of documents containing the word t
Let’s consider another straightforward example to illustrate how IDF can be computed. Imagine a corpus containing 1000 documents. If a particular word appears in all documents, its IDF value would be

If the word is present in 100 documents out of 1000, its IDF value would be

However, if the word only appears in 10 documents out of 1000, its IDF value would be

This example highlights that as the number of documents containing the word increases, the IDF value of the word decreases.
Now that we understand the calculation of TF and IDF, let’s explore how we derive TF-IDF values. To compute the TF-IDF value of a specific word in a document, we multiply its TF and IDF values together.
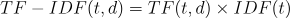
From our discussion, we understand that the TF-IDF value relies on:
- The frequency of the word in the document
- The total number of words in the document
- The total number of documents in the corpus
- The number of documents, including the word
If a particular word is included in all documents, its IDF value becomes zero and thus its IF-IDF value also becomes zero. Similarly, if a word is not included in a document, then its TF value for that document becomes zero and thus the TF-IDF value also becomes zero.
Cosine Similarities
We’ve gained the vector form of a data corpus using TF-IDF vectorization. Now it’s time to calculate how similar two vectors are. Cosine similarity, a metric used to calculate the likeness between two non-zero vectors within an inner product space, measures the cosine of the angle formed between the vectors. It’s calculated by dividing the dot product of the vectors by the product of their lengths. Notably, cosine similarity remains consistent regardless of the magnitudes of the vectors, solely relying on their angle. Its values range between -1 and 1, inclusive. For instance, identical vectors yield a similarity of 1, orthogonal vectors result in 0, and opposite vectors produce -1. In situations where vector components are non-negative, cosine similarity is confined within the range of 0 to 1. The formula of the Cosine Similarity (SC) is:

Where-
- A is a vector
- B is a vector
- A.B is the product of two vectors A and B
- ||A|| is the magnitude of the vector A
- ||B|| is the magnitude of the vector B

Conclusion
In conclusion, leveraging TF-IDF vectorization and cosine similarities offers a robust approach to identifying similar products in an e-commerce setting.
TF-IDF enables the transformation of textual product information into numerical data, capturing the significance of words within individual documents and across the entire corpus. By considering both term frequency (TF) and inverse document frequency (IDF), TF-IDF assigns weights to words that reflect their importance in distinguishing one document from another. This method addresses the limitations of simplistic bag-of-words approaches by giving more weight to distinctive words while downplaying the significance of overly common terms.
Cosine similarity, on the other hand, provides a metric for quantifying the similarity between two TF-IDF vectors. By measuring the cosine of the angle between the vectors, cosine similarity evaluates their directional agreement rather than their magnitudes, making it robust to variations in document lengths and scales. With values ranging from -1 to 1, cosine similarity offers a clear indication of the degree of similarity between vectors.
In summary, by employing TF-IDF vectorization and cosine similarities, e-commerce platforms can enhance their product recommendation systems, providing users with more accurate and relevant suggestions based on the textual information associated with each product. This approach facilitates dynamic and adaptive recommendations that consider the nuanced semantics of product descriptions, ultimately improving the user experience and driving engagement and sales.